

Pinterest Data Tech Stack
Read how Pinterest leverages multiple data technologies for exabyte scale data lake.

Pinterest, a tech company, processes enormous amounts of data daily. According to a 2014 article, this was around 20TB. Over a decade later, that number has significantly increased, with its S3 data lake now reportedly reaching exabyte scale, as mentioned in this AWS re:Invent 2023.
The tech stack shared below does not belong to one centralized data platform. Different teams own different components for different use cases. The goal of the article is to give holistic view of what data technologies are used at Pinterest.

Content is based on multiple sources including Tech Blog, Open Source websites, news articles. You will find references as you read.
Today’s post is brought to you by Schematic.

Pricing and packaging shouldn’t live in your code
Schematic brings pricing, packaging, and feature management together in one platform — so you can focus on building great products, not maintaining billing code.
See why high growth companies, from YC startups like Zep to scaling companies like BlackCloak and Automox, trust Schematic.
Platform
AWS
Pinterest leverages AWS as their data platform, utilizing several AWS services like EC2, S3, etc. for both offline and online processes.
“Pinterest’s exabyte data platform runs entirely on AWS”, as per this source.
Storage
S3
Pinterest has their exabyte-scale data lake on top of S3, while adding Generative AI capabilities recently.
📹 Recommended video: Pinterest extends existing data lake with generative AI
Iceberg
Iceberg has been recently adopted after their move to Trino. It works well with data lake on S3 to provide a seamless lakehouse architecture.
📹 Recommended video: Iceberg at Pinterest.
StarRocks
Pinterest recently transitioned from a popular data store Druid to StarRocks for real-time analytics, gaining faster performance and enhanced SQL querying support.

TiDB
In 2022, Pinterest migrated from HBase to TiDB after using it for a decade as their NoSQL Datastore, supporting diverse use cases as shown below.
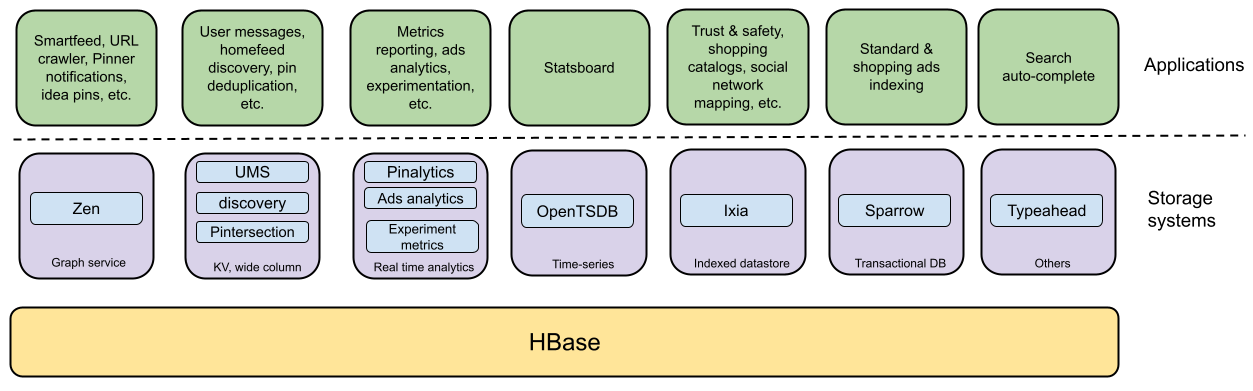
As per article, the primary reasons for adopting TiDB were lower infrastructure costs, enhanced functionalities (such as distributed ACID transactions), and reduced operational overhead.
📖 Recommended Reading: HBase vs TiDB
Snowflake
According to this source, Snowflake serves as a data warehousing solution for enterprise analytics, offering role-based access controls (RBAC) to manage sensitive data. The primary purpose is to use it as a data source for Tableau.
Processing
Kafka
Kafka is used as a centralized system for routing events in real time to multiple different consumers.
As of December 2020, there were 50+ clusters, 3,000+ brokers, 3,000+ topics, and ~500K partitions (including replicas): source.
Airflow
Pinterest has their own version of Airflow known as Spinner, they have enhanced the scheduler to support massive scale e.g. multi scheduler support.
Flink
Pinterest’s Xenon, a Flink based service supports multiple real time use cases; ads, shopping, experimentation, etc. It consumes data from Kafka and output to Kafka, StarRocks, etc.
Trino
At Pinterest, Trino enables performant and efficient querying of petabyte-scale data in the Lakehouse using SQL. In 2023, they migrated to AWS Graviton, achieving a 2x efficiency improvement.
Spark
Despite the presence of Flink and Trino, Spark remains an option for users for scheduled querying, interactive querying, or real-time processing for large scale datasets.
Dashboard
Tableau
Pinterest uses Tableau for enterprise analytics reporting, integrated with Snowflake (see Snowflake under Storage section).
Custom Tool
Pinterest is a large-scale platform, and given their tools like Pinterest Analytics, they likely have an in-house solution for internal use cases. However, information about it is not publicly available.
Related Content: Tech Stack Series


💬 Pinterest use variety of data technologies across different teams. If you think I missed important ones, feel free to comment below.
Aside from Flink, what other tools or frameworks is Pinterest using for data ingestion? I assume that not all of Pinterest's data sources are real-time. Do you have any insight into how they handle batch loading of database or file-based data into Snowflake or Iceberg? Are they leveraging Snowflake to ingest data into managed Iceberg tables? Additionally, where does Pinterest use Iceberg for table storage compared to storing data internally within Snowflake?
This provides a helpful overview, but it doesn't quite capture the full picture.