




Data Pipeline - Incremental vs Full Load
Learn the pros, cons and use cases about the data pipeline design patterns, full load and incremental commonly used across the industry.

I assume you have seen my previous article where I covered Data Engineering end to end where I shared high level scope, this article will focus on one of the core components from it `Design Patterns` covering the two popular approaches Incremental and Full Load.
In this article, we will cover important aspects of the Incremental and Full Load Patterns, we will go over:
High level examples
Benefits
Challenges with their Solutions
Use cases
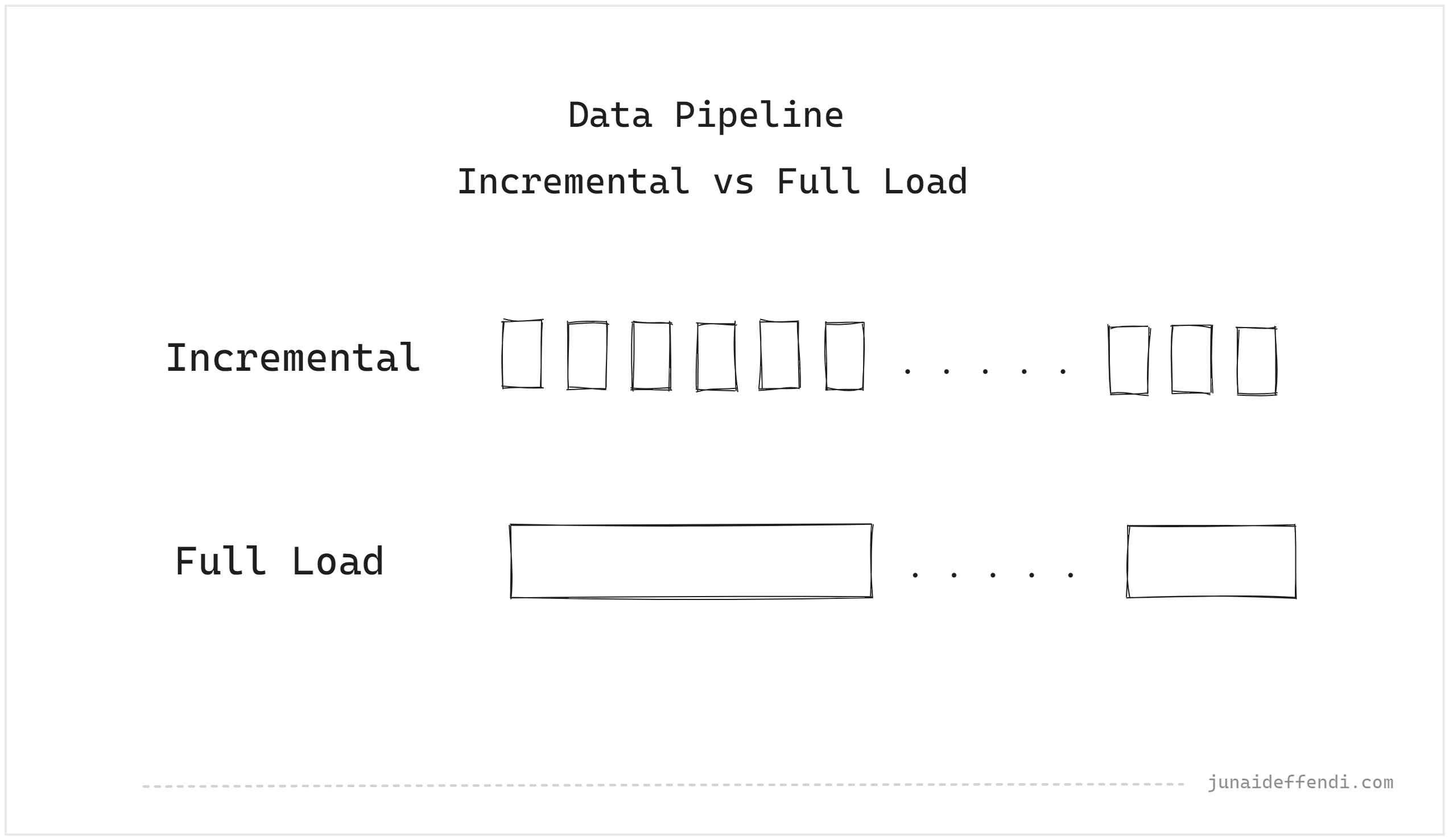
Incremental
Incremental Pipeline processes data in increments, where increment can be of any size depending on the use case. These can be of either a batch or a streaming. E.g.
A batch pipeline that processes data in increments, like daily runs that processes the last 24 hours of data from a streaming source, a daily run that processes a daily data from a batch source like file drop.
A streaming pipelines is a incremental pipeline by default, it processes data in increments or micro batches, like a streaming pipeline that runs 24/7 fetching data from the queue in near real time.
Benefits
Cost effective as it processes a subset.
Quicker to recover and reprocess in case of failures due to shorter run times.
Provides opportunity for shorter SLAs.
Challenges & Solutions
When upstream data source is batch, backfilling becomes a challenge as it require additional functionality depending on the design and requirements. To tackle this:
A separate pipeline may be required to process data from certain point in history using time ranges.
If business logic changes frequently that require a backfill then this may feel like a full load approach.
When upstream data source is streaming, late arriving data needs attention. You are expected to have late arriving data which may not be processed in the given run. To tackle this:
Overlap time window while handling duplicates through `Upserts` or Async `DeDup` job depending on the use case.
Provide flexibility in a pipeline to go back to certain time range to do a mini backfill, happens only when there is an incident with the upstream source.
This does not apply if the incremental pipeline is itself a streaming as it will eventually catch up.
Full Load
Full load pipeline processes the whole dataset. This is suited for batch. E.g.
A batch pipeline that processes the entire dataset, like a daily drop of file triggers the pipeline that reads the whole history.
Benefits
Backfilling is not a concern as every run processes the whole history, no separate pipeline or functionality required.
Snapshot versioning makes it easy to compare between different versions of data when needed.
Very east to maintain and build a pipeline.
Challenges & Solutions
Compute heavy and slower to process since it runs on full set. To tackle this:
Optimization can be considered to reduce run time and compute cost. Learn optimization techniques:
Storage costs can be super high as it stores multiple version of full copy of data. To tackle this:
Setting retention policies is a good approach.
Harder to recover from failed state as it could take quite a long time to rerun. To tackle this:
Checkpointing data into intermediate temporary storage can speed up.
In ETL/ELT, the L (load) can take quite a bit of time depending of data size. To tackle this:
Estimating the load time and set the SLAs accordingly.
Use Cases
Lets look at how to pick one over the other using the common factors to check:
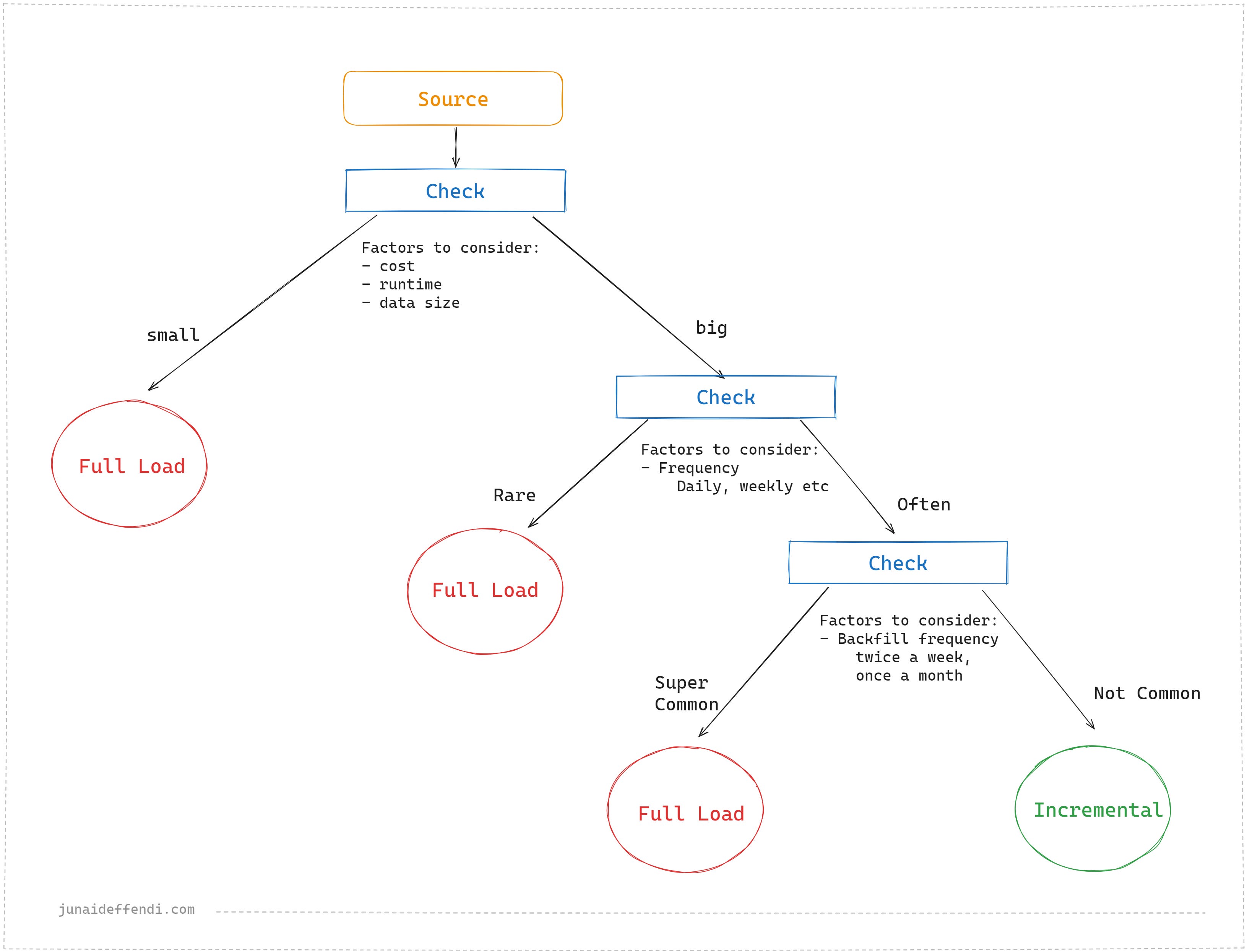
Let me know in the comments, which one do you use and how you make the most of it.
Related content:
Incremental Processing by Netflix
Design Patterns by Joseph Machado
Exciting Content:

Top picks from Data Engineering:
Top picks from the community:
Learnt something new today.
Thanks for sharing my article as well 🙏
thanks for sharing